TD - Le Li�vre et la Tortue
Contexte
2 fichiers lièvre-iso-8859-1.html et lièvre-utf8.html contiennent le même texte : la fable du lièvre et de la tortue de Jean de La Fontaine.
 Source : Wikipédia
Source : Wikipédia
Si on ouvre ces 2 fichiers dans un navigateur Web, des symboles étranges apparaissent, rendant la lecture inconfortable.
Ce TD a pour but de comprendre l'origine de ce phénomène.
Cette séance se découpe en 2 parties :
- La première consiste à explorer et découvrir la problématique d'encodage,
- La deuxième consiste à manipuler la représentation des chaines de caractères en python.
Les parties doivent être traitées dans l'ordre.
Pré-Requis
Avoir l'extension Set Character Encoding installée sur votre poste.
Partie 1 - Exploration et découverte
Cette partie vise à vous faire comprendre le problème d'encodage par différentes observations, calculs et manipulations à réaliser.
A la fin de cette partie, vous devez répondre à un questionnaire et le valider avec votre professeur.
En cas de réussite, vous pouvez aborder la partie 2.
Table d'encodage et calcul de la représentation binaire
ISO-8859-1
Voici la table d'encodage ISO-8859-1 :
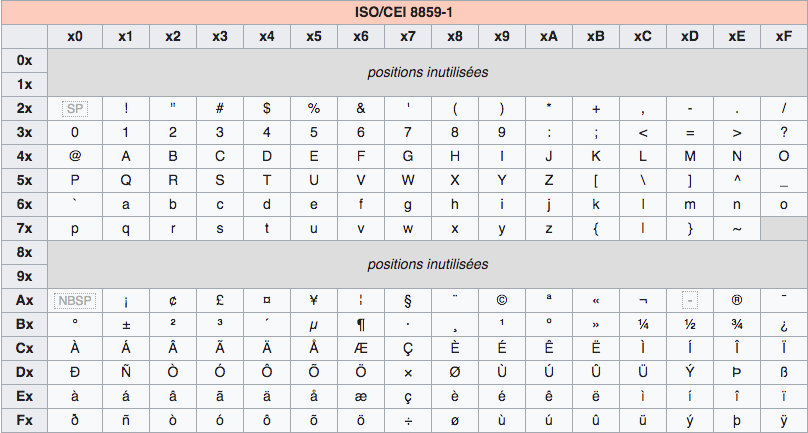
Exemple : la point de code du caractère A est 41 (ligne 4x et colonne x1).
Observation 1. Sachant que l'encodage ISO-8859-1 représente les points de code sur 1 octet. Quelle est la représentation binaire du caractère A ?
Le point de code du caractère A est \(41_{16}\) soit \(0100\,0001\) en binaire.
Observation 2. Quelle est le point de code du caractère < ? Quelle est sa représentation binaire ?
Le point de code du caractère < est \(3C_{16}\) soit \(0011\,1100\) en binaire.
Observation 3. Quelle est la point de code du caractère à? Quelle est sa représentation binaire ?
Le point de code du caractère à est \(E0_{16}\) soit \(1110\,0000\) en binaire.
Observation 4. Étant donné le mot binaire \((10101001)_2\), quel caractère représente-il ? Quel est celui associé au mot binaire \((11110100)_2\) ?
- \((10101001)_2 = \text{A}9_{16}\), soit le point de code lié au caractère
©. - \((11110100)_2 = \text{F}4_{16}\), soit le point de code lié au caractère
ô.
Unicode UTF-8
La table d'encodage de l'UTF-8 est plus conséquente que celle de l'encodage ISO-8859-1. Le site https://unicode-table.com/fr permet d'obtenir les correspondances entre les caractères, leur point de code ainsi que leur représentation binaire UTF-8.
Exemple : le caractère © a le point de code U+00A9 (U+ symbolise le fait que l'encodage est Unicode), soit le 169ème point de code (\((A9)_{16} = (169)_{10}\)) dans la table d'encodage.
Observation 5. En vous référant au cours sur l'encodage UTF-8, calculez la représentation binaire UTF-8 de ce caractère.
La représentation binaire du point de code est \((10101001)_2\), qui nécessite 8 bits.
Selon la règle de codage UTF-8, 2 octets sont nécessaires pour représenter en binaire UTF-8 le caractère, sous la forme : \(110XXXXX\,10XXXXXX\) où X représente les bits de la représentation binaire du point de code.
La représentation binaire UTF-8 est : \(11000010\,10101001\).
Observation 6. Cherchez le point de code et la représentation binaire du caractère ♧.
Le point de code du caractère ♧ est 2667. La représentation binaire du point de code est : \(2667_{16} = 0010\,0110\, 0110\,0111_2\), qui nécessite 16 bits.
Selon la règle de codage UTF-8, 3 octets sont nécessaires pour représenter en binaire UTF-8 le caractère, sous la forme : \(1110XXXX\,10XXXXXX\,10XXXXXX\) où X représente les bits de la représentation binaire du point de code.
La représentation binaire UTF-8 est : \(11100010\,10011001\,10100111\).
Observation 7. Cherchez le point de code et le caractère associés à la représentation binaire \((11100010\,10000100 \,10111100)_2\).
La représentation binaire UTF-8 du caractère est sur 3 octets, sous la forme \(1110XXXX\,10XXXXXX\,10XXXXXX\) où X représente les bits de la représentation binaire du point de code.
La représentation binaire du point de code est : \(0010\,0001\, 0011\,1100_2\), Soit \(213C_{16}\).
Le caractère associé est : ℼ.
Effet visuel du problème d'encodage
Observation 8. Ouvrez dans votre navigateur Web les fichiers lièvre-iso-8859-1.html et lièvre-utf8.html.
Quelles différences constatez-vous ?
Des caractères bizarres apparaissent.
Observation 9. Dans l'explorateurs de fichiers, comparez la taille de ces 2 fichiers (en octets). Quelles différences constatez-vous ?
- ISO-8859-1 : 1385 octets,
- UTF-8 : 1418 octets.
Observation 10. Dans votre navigateur Web, en faisant clic droit sur le page lièvre-iso-8859-1.html, changer la valeur de Set Encoding character avec les autres valeurs que celle sélectionnée. Que constatez-vous ?
Observation 11. Dans votre navigateur Web, en faisant clic droit sur le page lièvre-utf8.html, changer la valeur de Set Encoding character avec les autres valeurs que celle sélectionnée. Que constatez-vous ?
Les caractères bizarres disparaissent au profit d'accents.
Analyse de la représentation binaire d'un fichier texte
Nous allons utiliser un éditeur hexadécimal de texte en ligne https://www.onlinehexeditor.com/, il permet de visualiser le contenu réel d'un fichier texte, i.e les mots binaires (en héxadécimal) qui représentent les caractères.
Observation 12. Dans votre navigateur Web, rendez-vous sur la page https://www.onlinehexeditor.com/ et ouvrez les 2 fichiers lièvre-iso-8859-1.html et lièvre-utf8.html en cliquant sur open file. Quelles différences constatez-vous ?
Observation 13. Au vu des observations précédentes, comment expliquez-vous que votre navigateur affiche :
LiÚvreau lieu delièvrequand on ouvre le fichierlièvre-utf8.htmlavec un encodage iso-8859-1 ?t�moignageau lieu detémoignagequand on ouvre le fichierlièvre-iso-8859-1.htmlavec un encodage UTF-8 ?
Questionnaire
Q1. le caractère à a toujours la même représentation en mémoire quelque soit l'encodage utilisé ?
A. Vrai B. Faux [X]
Q2. Dans la table d'encodage Unicode, le caractère Ô est le :
A. 212ème [X] B. 213ème C. \((D4)_{16}\)ème [X] D. Il n'existe dans la table d'encodage Unicode
Q3. En UTF-8, les caractères sont représentés sur :
A. 1 octet B. 2 octets C. 7 bits D. un nombre variable entre 1 et 4 octets [X]
Q4. En cas de problème d'affichage visuel d'un texte, quelle(s) est(sont) la(les) solution(s) selon vous ?
A. s'assurer que l'encodage du fichier et le même que celui qui sert à l'affichage [X] B. modifier le fichier pour corriger les erreurs C. appeler son professeur pour qu'il corrige le problème D. modifier l'encodage de la visualisation [X]
Q5. Soit le point de code U+00D4, cela vous indique que :
A. l'encodage est Unicode et la représentation binaire du caractère est \((01001101)_2\) B. l'encodage est Unicode et la représentation binaire du caractère est \((11000011 \,10010100)_2\) [X] C. l'encodage est Unicode et le caractère associé est la lettre Ô [X] D. l'encodage est ISO-8859-1 et la représentation binaire du caractère est \((01001101)_2\)
Q6. Quand une application traite un fichier encodé en iso-8859-1 :
A. Elle traite octet par octet [X] B. Elle traite un nombre variable d'octets C. calcule la position en fonction de la valeur de l'octet et affiche le caractère associé [X] D. affiche les caractères en fonction de la table d'encodage Unicode
Partie 2 - Manipulation en Python
Q1. Dans un interpréteur Python, exécutez successivement les instructions chr(212) et chr(169). Qu'en déduisez-vous sur la spécification de la fonction chr?
chr donne le caractère associé au point de code passé en paramètre.
Q2. Dans un interpréteur Python, exécutez successivement les instructions ord('©') et ord('à'). Qu'en déduisez-vous sur la spécification de la fonction ord?
ord donne le point de code du caractère passé en paramètre.
Q3. Écrire une fonction binaire_utf8, qui prend en paramètre un point de code Unicode sous la forme d'un entier et renvoie la représentation binaire UTF-8 du caractère associé, sous la forme d'une liste d'octet (un octet est une liste de bits). (Aide : Vous pouvez réutiliser les fonctions de conversion en binaire des précédentes séances ainsi que la méthode vu en cours)
def binaire_utf8(code):
binaire_code = binaire(code)
if len(binaire_code) < 8:
return binaire_code
elif 8 <= binaire_code < 12:
return '110' + binaire_code[:5] + '10' + binaire_code[5:]
elif 12 <= binaire_code < 17:
return '1110' + binaire_code[:4] + '10' + binaire_code[4:10] + '10' + binaire_code[10:]
elif 17 <= binaire_code:
return '11110' + binaire_code[:3] + '10' + binaire_code[3:9] + '10' + binaire_code[9:15] + '10' + binaire_code[15:]
Q4. Écrire une fonction str_to_utf8, qui prend en paramètre une chaine de caractère et renvoie la représentation binaire UTF-8, en hexadécimal, de l'ensemble des caractères de la chaine. Exécutez votre fonction sur la chaine Rien ne sert de courir ; il faut partir à point. Le Lièvre et la Tortue en sont un témoignage. Comparez le résultat obtenu avec celui de l'observation 12.
def str_to_utf8(chaine):
l = []
for caractere in chaine:
l.append(hexadecimal(binaire_utf8(ord(caractere))))
return l
Dernière mise à jour : 13/11/2023